Dokumenty Google (Google Docs) dorobiły się nowej funkcji, mowa o OCR (ang. Optical Character Recognition), czyli mówiąc po ludzku: rozpoznawanie tekstu z plików graficznych (rastera), np. z zeskanowanej strony wybranej książki.
Żeby za dużo na ten temat nie pisać, po prostu zobaczcie, jak to wygląda.
Po zalogowaniu do naszego konta na stronie docs.google.com, znajdziemy przycisk prześlij, zobaczymy następujący ekran:
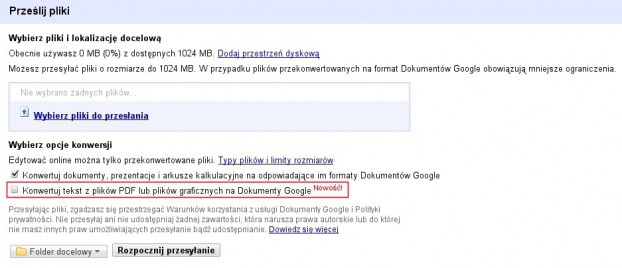
Jak widać doszła nowa funkcja: “Konwertuj tekst z plików PDF lub plików graficznych na Dokumenty Google“, dodajemy nasz plik do zeskanowania i wybieramy tę opcję. Ja zrobiłem zrzut kawałka wpisu: Koncepcja: Tablet Microsoft Courier vs Rzeczywistość: Toshiba Libretto W100, zapisałem do jpeg’a i właśnie ten plik poddałem ponownemu skanowaniu OCR.
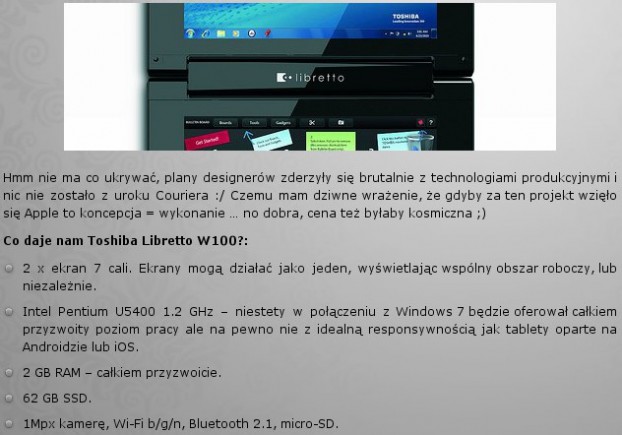
Po zakończeniu procesu wybrałem skonwertowany plik i usługa przeniosła mnie do dokumentu, który wyglądał w ten sposób:

Pojawił się tekst, który wreszcie możemy edytować. Na górze widać informacje o dokonanym konwertowaniu, o braku formatowania i o tym, że niecały tekst mógł być rozpoznany (braki, błędy). Bądźmy szczerzy, ideał to to nie jest, brak polskich znaków (nie są rozpoznawane, na szczęście nie wycina ich), brak formatowania jest sporym utrudnieniem. Jednak trzeba być uczciwym, zdjęcie do rozpoznawania było bardzo małej rozdzielczości, dlatego biorąc to pod uwagę można śmiało uznać, że ta jakość rozpoznawanie nie jest wcale taka zła. Na pewno ułatwi wielu osobom życie, w tym mnie, zwłaszcza przy PDF’ach.
Jedna rzecz, na którą zwróciłem jeszcze uwagę to, to że gdy tekst jest napisany jasną czcionką (białą w testowanym przypadku) na czarnym tle, to system niespecjalnie sobie z tym radzi – taki tekst nie jest rozpoznawany. Być może w przyszłości to poprawią.